
📌 Intro
Object Detection(객체 인식) 분야에서 널리 사용되고 있는 YOLO에 대해 알아보도록 하겠다.
📌 Object Detection?
Object Detection, 객체 검출이란 이미지나 움직이는 영상에서 미리 정의한 객체를 찾아내는 것을 말한다. 단순히 고양이 이미지을 보고 고양이라고 분류하는 것과는 완전히 다른 영역의 문제인 것이다. 각각에 대해 정리하면 다음과 같다.
- Classification : 여러 물체에 대해 어떤 물체인지 클래스를 분류하는 문제
- Localization : 물체가 어디 있는지 박스를 통해 위치 정보를 나타내는 문제
- Object Detection : Classification과 Localization을 동시에 진행하는 것
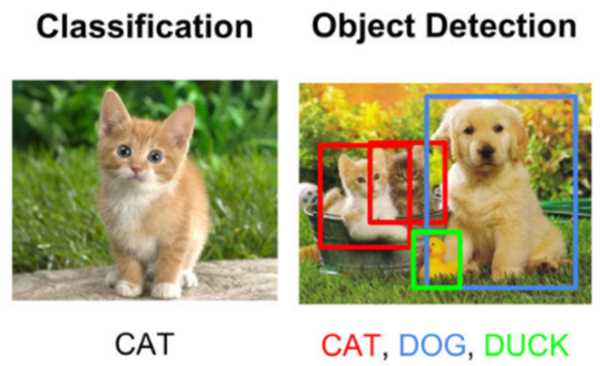
위 그림에서 Classification과 Object Detection의 차이를 살펴볼 수 있는데 한 이미지에 여러 객체가 있다면 각 객체에 대해 Localization을 통하여 Bounding Box를 치고 어떤 객체인지 분류까지 진행하는 것을 Object Detection이라고 한다.
여기서 Bounding Box란 오른쪽에 있는 사진처럼 각 객체에 대해 어디에 위치하는지 박스로 표시해주는 것을 말한다.
📌 YOLO?
이번엔 YOLO에 대해 알아보자.
YOLO는 You Only Look Once의 약자로 이미지를 한 번만 보면 객체를 검출할 수 있다는 뜻이다.
앞서 살펴본 객체 탐지 방법을 크게 1-Stage Detector와 2-Stage Detector 두 가지로 나눌 수 있다.
이 중 YOLO는 1-Stage Detector방식에 속한다. (2-Stage Detector의 대표적인 예로 RCNN, Fast R-CNN, Faster R-CNN이 있다.)
1-Stage Detector와 2-Stage Detector의 차이를 간단하게 살펴보면 2-Stage Detector는 이미지에서 Region Proposal단계에서 객체가 있을만한 곳을 찾고 Classification로 넘어간다.
이에 비해 1-Stage Detector는 Region Proposal이라는 단계 없이 한 번에 객체 탐지를 수행한다. 때문에 객체 탐지를 하는데 소요되는 시간은 적게 들지만 그만큼 정확도가 줄어들 수 있다.
그래서 객체 탐지 분야에서 정확도와 소요시간은 Trade-Off 관계에 있다고 볼 수 있다.
YOLO는 하나의 입력 이미지를 S x S그리드로 나눈다. 만약 어떤 객체의 중심이 특정 그리드 셀안에 위치한다면 해당 그리드 셀이 그 객체를 검출해야 한다.
각각의 그리드 셀은 B개의 Bounding Box에 대한 Confidence Score를 예측한다. 여기서 confidence Score란 Bounding Box가 얼마나 정확한지를 나타낸다.
각각의 Bounding Box는 x, y, w, h, confidence로 총 5개의 값으로 구성되어 있다.
(x, y)는 그리드 셀 내의 Bounding Box의 상대적 중심위치를 의미한다. 상대 위치이기 때문에 0~1사이 값을 갖는다.
(w, h)는 Bounding Box의 상대 너비와 상대 높이를 의미한다. 그리드 셀의 전체 너비와 높이를 1로 보고 상대적인 너비와 높이를 의미하기 때문에 w와 h도 역시 0~1사이의 값을 갖는다.
하나의 그리드에 여러 개의 Bounding Box가 존재한다고 하더라도 하나의 그리드에서는 오직 하나의 클래스에 대한 확률 값을 구한다. 앞에서 B개의 Bounding Box를 예측한다고 했는데 이와는 관계없이 항상 하나의 클래스만 예측하는 것이다. 이 때문에 YOLO는 겹쳐져 있는 모델을 잘 찾지 못한다.
마지막으로 Bounding Box에 특정 클래스가 나타날 확률과 예측한 Bounding Box가 그 클래스에 얼마나 잘 들어맞는지를 계산하여 결과가 나오게 된다.
Overview
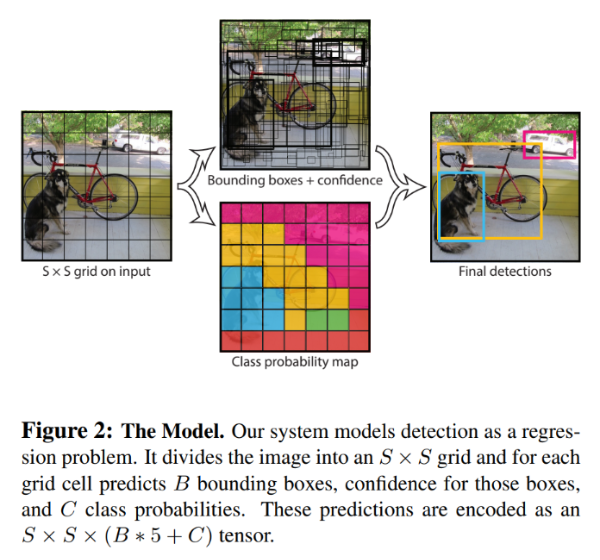
그림을 보면서 조금 더 자세하게 알아보자.
input 이미지가 들어오면 네트워크를 통과하여 가운데 2개의 이미지([Bounding boxes + confidence], [Class probability map])의 결과물을 얻는다.
네트워크에서는 input 이미지를 7 x 7의 그리드로 나눠주고 각 그리드에서 중심을 안쪽으로 하여 크기가 일정하지 않은 바운딩 박스를 2개씩(B=2) 생성한다. 그리드가 총 49개니 바운딩 박스는 총 98개가 될 것이다. 그리고 객체가 있을 확률이 높다고 판단되는 바운딩 박스는 더 두껍게 그려준다.
NMS(Non Maximal Suppression)방법을 이용하여 신뢰도가 가장 높은 바운딩 박스를 남겨주면 Final detections의 이미지처럼 총 3개의 바운딩 박스가 남게된다.
Class probability map은 그리드 셀별로 어떤 클래스의 객체가 있는지 색으로 표시한 이미지다. (색상이 다르면 클래스도 다름) 따라서 총 5개의 객체가 있다고 판단한 것이다.
결과적으로 NMS를 통해 남은 바운딩 박스와 Class probability map을 합쳐주면 어느 위치에 어떤 객체가 존재하는지 표시할 수 있고 Final detections와 같은 결과 이미지를 얻을 수 있다.
Network 구조
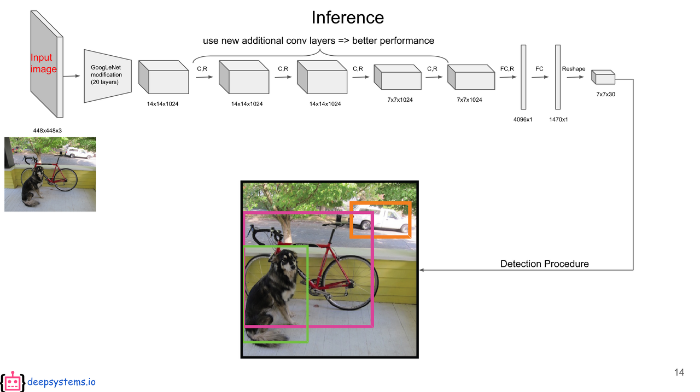
논문에서 S = 7, B = 2, C = 20 이 할당되어 있다. S는 그리드의 수, B는 하나의 그리드 셀에서 생성하는 바운딩 박스의 수, C는 클래스의 개수이다.
24개의 Convolution Layer와 2개의 Fully Connected Layer를 사용하고 결과는 7 X 7 X 30으로 나오게 된다. 7 X 7인 이유는 S를 7로 설정했기 때문이다.
Inference 과정
Deep Systems의 슬라이드를 인용하였다.
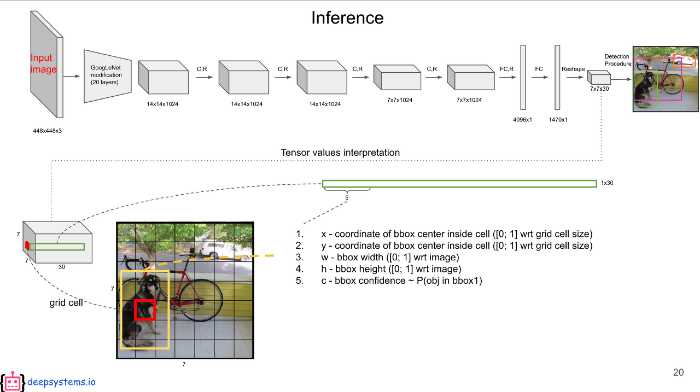
결과로 나오는 7 X 7 X 30 중 7 X 7은 49개의 그리드 셀을 의미한다. 각 그리드 셀은 2개(B=2이기 때문)의 바운딩 박스를 가지고 있는데 30중 앞의 5개의 값은 각 그리드 셀의 첫 번째 바운딩 박스에 대한 값이 채워져있다. 각 값은 앞에서 설명했던 것처럼 x, y, w, h, confidence score다.
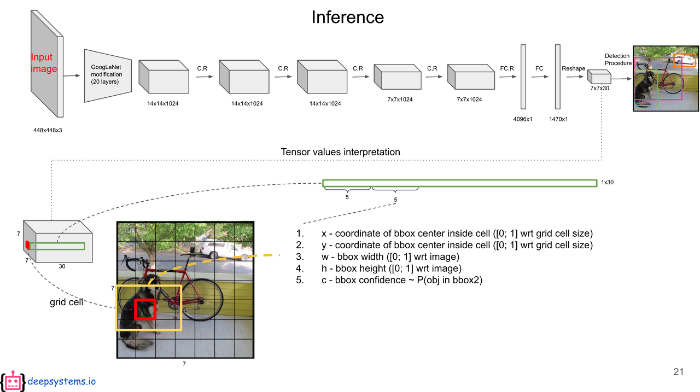
30중 6~10번째 값은 두 번째 바운딩 박스에 대한 값이고 이 역시 x, y, w, h, confidence score다.
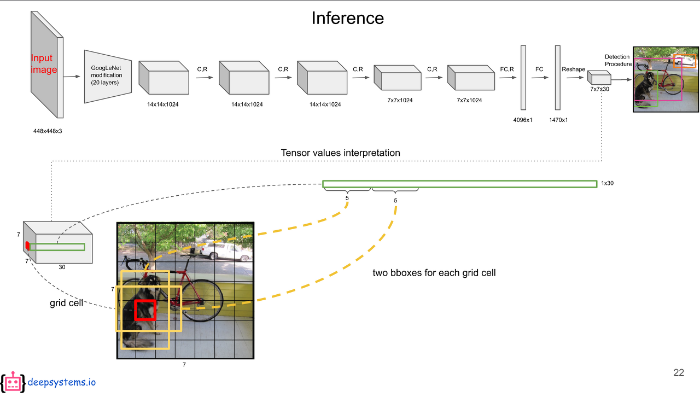
두 개의 바운딩 박스를 겹쳐 보여주면 위 그림과 같다.

30중 나머지 20개의 값은 각 클래스에 대한 conditional class probability다.

첫 번재 바운딩 박스의 confidence score와 각 conditional class probability를 곱하면 첫 번째 바운딩 박스의 class specific confidence score가 나온다.
두 번째 바운딩 박스역시 첫 번째 바운딩 박스의 계산과 동일하게 진행하면 두 번째 바운딩 박스의 class specific confidence score가 나온다.

위에서 진행한 계산을 모든 그리드셀에 있는 모든 바운딩 박스에 대해 계산하면 총 98개의 class specific confidence score가 나오게 될 것이다. 98개의 class specific confidence score에 대해 각 클래스 별 NMS(Non Maximal Suppression)연산을 진행하고 클래스 별 바운딩 박스의 위치를 결정한다.
Comparison
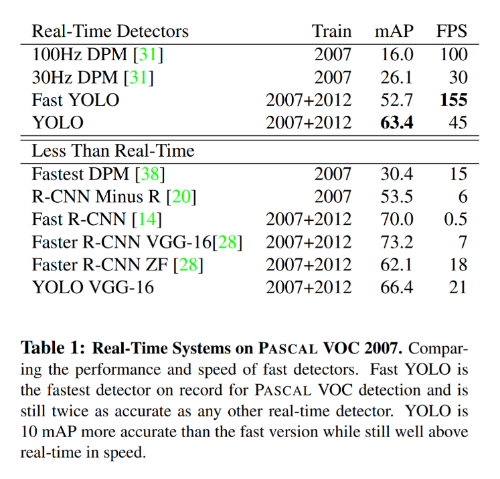
위 표는 다른 객체 탐지 분야에서 사용되는 모델들과 YOLO의 성능을 비교한 표다. 1-Stage Detector이기 때문에 2-Stage Detector보다 FPS가 높은 것을 볼 수 있다.
mAP는 모델의 성능을 나타내는 지표로 사용되는 값인데 2-Stage Detector보다 값이 낮지만 그렇게 뒤쳐지지 않는 성능을 보여준다. mAP관련해서는 추후에 정리할 예정이다.
📌 정리
지금까지 Object Detection에 대한 내용과 YOLO에 대해 정리해보았다. 내가 이해한 내용을 바탕으로 글을 써내려가는게 얼마나 어려운 것인지 한번 더 깨닫게 되었고, 내용을 한 줄 적을 때마다 이해한 것이 맞는지 확인하며 작성했기 때문에 시간도 오래걸렸지만 그만큼 더 깊이 이해했고, 잘못된 이해는 바로잡을 수 있었다.
다른 분들의 논문 리뷰를 보고 내 글을 보면 내용도 부실하고 얕은 느낌이 들지만 네트워크 아키텍쳐 자체를 이해하기 위한 사전 지식이 부족하기 때문에 어쩔 수 없는 부분인 것 같다. 더 공부를 진행하면서 부족함이 느껴지만 글을 보충하는 것이 좋을 것 같다.
위 표에서도 보이지만 YOLO가 다른 네트워크들보다 성능과 속도면에서 좋은 결과를 보여주기 때문에 가장 널리 사용되는 것으로 생각되고 github에서 관리가 잘 진행되고 있고, 질문 글도 많이 올라오기 때문에 사용하기에도 편리하다고 생각된다.
다음은 실제로 YOLOv5를 어떻게 사용하는지에 대해 정리할 것이다.
📌 참고
[1] https://89douner.tistory.com/75
[2] https://nuggy875.tistory.com/20
[3] https://bkshin.tistory.com/entry/논문-리뷰-YOLOYou-Only-Look-Once
[4] https://github.com/ultralytics/yolov5
[5] https://blog.naver.com/sogangori/220993971883
[6] https://curt-park.github.io/2017-03-26/yolo/