
📌Intro
AI나 머신러닝 혹은 딥러닝에 대해 공부를 하고있는 사람이라면 거의 대부분이 시작을 MNIST로 했을 것이라 생각하고 나 역시 그렇다. 이쪽 분야의 지식이 풍부한 것은 아니지만 공부한 내용을 정리하며 이해를 높이려한다.
모델을 만들고, MNIST 데이터를 이용하여 손글씨 분류기 모델의 학습과 추론과정에 대해 알아보도록 하자.
📌MNIST Data?
먼저 MNIST 데이터에 대해 설명이 필요할 것 같다. MNIST 데이터는 여러명의 사람들이 손으로 쓴 숫자들로 이루어진 데이터베이스다.
이미지의 크기는 28X28X1이며 아래와 같이 60,000개의 트레이닝 이미지와 10,000개의 테스트 이미지로 구성되어 있다.


각 데이터 셋은 이미지와 라벨이 매핑되어 있는 형태인데, 여기서 이미지는 손글씨 사진을 의미하고, 라벨은 손글씨에 대한 참 값을 의미한다. 만약 아래와 같은 사진이 있다면 라벨은 0이 될 것이다.

📌Input & Output
우리의 목표는 손글씨 분류기 모델을 만드는 것이다. 그렇다면 Input과 Output은 무엇일까?
Input은 크기가 28X28X1인 grayscale의 손글씨 이미지이고, Output은 크기가 1x10인 이미지의 라벨이다.
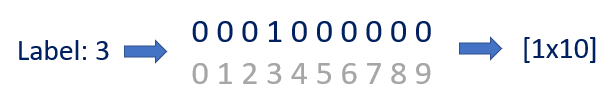
위 사진은 라벨이 3일 때의 1X10 크기인 Output을 보여준다.
📌코드 설명
그렇다면 이제 직접 코드를 이용하여 모델을 생성하고 훈련과 추론까지 진행해보자.
1. 패키지 import
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plttensorflow는 딥러닝 모델의 생성과 훈련 및 추론을 하기 위해 import하였다.
numpy는 MNIST 데이터가 numpy 형태로 되어있기 때문에 import 하였다.
matplotlib은 불러온 이미지를 시각화하여 보기위해 임포트 하였다.
2. MNIST dataset import
# 1. MNIST data set import
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()tensorflow에서 직접 MNIST 데이터를 불러와 사용할 수 있다.
load_data()함수는 x_train, y_train, x_test, y_test 네 개의 NumPy Array를 반환한다.
3. 데이터 확인
현재 데이터가 어떤식으로 구성이 되어있는지 이해가 안될 수 있기 때문에 직접 확인해보도록 하자.
# (1) training, test set 개수
print(x_train.shape)
print(x_test.shape)
# (2) 0번째 원소의 정보 출력
print("Image Shape : ", x_train[0].shape)
print("Image Label : ", y_train[0])(1)

현재 트레이닝 데이터는 60,000개이며 28X28의 이미지인 것을 확인할 수 있다.
(2)

트레이닝 데이터의 첫 번째 원소의 Shape과 Label과 함께 이미지를 흑백으로 출력하여 확인한 결과이다.
3. 모델 구성
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)tensorflow.keras.models.Sequential()함수를 이용하여 모델을 구성한다.
입력층 (Input layer)에서 Flatten()을 이용해서 28×28 픽셀의 값을 784개의 1차원 배열로 변환한다.
다음으로 두 개의 뉴런 층 (Neuron layer)은 Dense()를 이용해서 완전 연결된 층 (Fully-connected layer)를 구성한다. 각 층은 512개와 10개의 인공 뉴런 노드를 갖고 활성화 함수 (activation function)로는 각각 ReLU (tf.nn.relu)와 소프트맥스 (tf.nn.softmax)를 사용한다.
4. 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])5. 모델 요약
model.summary()

모델의 레이어 수, 학습 파라미터 개수, 결과 Shape등 모델의 요약정보를 알 수 있다.
6. 모델 훈련
history = model.fit(x_train, y_train, validation_split=0.1, epochs=5)
모델 훈련 시 epoch와 batch_size 등 다양한 파라미터를 지정할 수 있다.
validation_split은 훈련시 사용하는 데이터에서 validation_split만큼을 떼어 매 에포크마다 정확도 테스트를 진행할 때 사용한다.
이를 사용하는 이유는 모델의 정확도를 훈련하며 확인할 수 있고 이로 인해 과적합을 막을 수 있기 때문이다.
7. 훈련 과정 확인
print(history.history.keys())
train_accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(list(range(5)), train_accuracy, 'b', label='Training accuracy')
plt.plot(list(range(5)), val_accuracy, 'r', label='Validation accuracy')
plt.title("Training and validation accuracy")
plt.legend()
plt.show()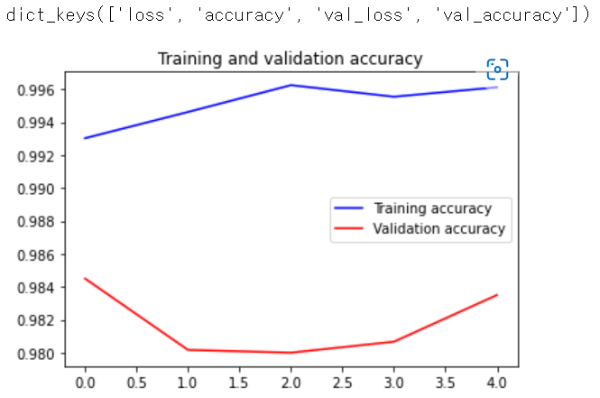
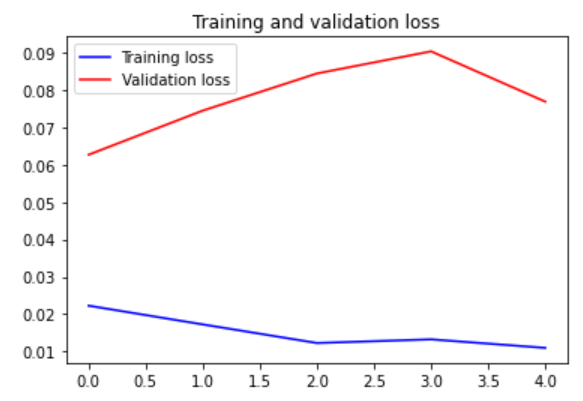
매 에포크마다 training data와 validation data에 대한 accuracy와 loss를 확인할 수 있다.
8. 모델 평가
test_loss, test_acc = model.evaluate(x_test, y_test) print("Accuracy : ", test_acc)
학습을 통하여 얻은 모델을 테스트 데이터로 평가한다. 결과로 loss와 compile에서 요청한 'metrics'를 반환한다.
우리가 생성한 모델의 정확도는 98%인 것을 확인할 수 있다.
9. 결과 확인
n = 0
plt.imshow(x_test[n].reshape(28, 28), cmap = 'Greys', interpolation = 'nearest')
plt.show()
print("The predictions are ", model.predict(x_test[n].reshape((1,28,28,1))))
print("The answer is ", np.argmax(model.predict(x_test[n].reshape((1,28,28,1)))))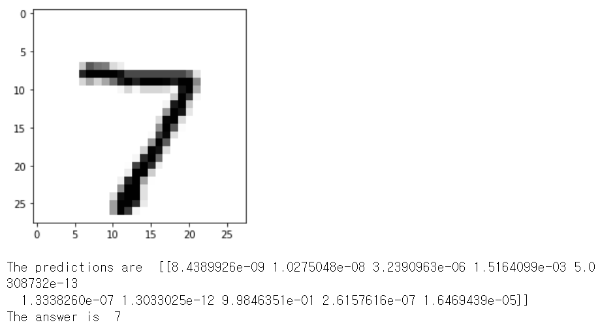
손글씨가 7인 이미지를 보고 정답이 7이라고 잘 인식한 것을 확인할 수 있다.
📌 함수에 대해 더 알아보자
MNIST data를 이용하여 모델을 직접 구성하고, 훈련, 테스트까지 진행해보았다. 그 과정에서 여러 함수들이 사용되었는데 하나씩 살펴보자.
1. compile
훈련을 위한 모델의 구성을 구성한다.
compile(optimizer, loss=None, metrics=None, loss_weights=None,
sample_weight_mode=None, weighted_metrics=None, target_tensors=None)- optimizer : 어떤 옵티마이저를 사용할 것인지 정한다.
- loss : 어떤 손실 함수를 사용할 것인지 정한다.
- metric : 어떤 항목을 측정할 것인지 정한다. ex) 정확도, 오차, MAE 등
- loss_weights : 손실에 따른 가중치 부여 값을 지정하는 것이다.
- sample_weight_mode : 시간 경과에 따른 가중치 부여 지정이다.
2. fit
모델을 실제로 훈련하도록 한다.
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None,
validation_split=0.0, validation_data=None, shuffle=True, class_weight=None,
sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None,
validation_freq=1)3. evaluate
학습에서 얻은 모델을 테스트 데이터로 평가한다.
테스트 데이터로 돌려 얻은 손실값과, compile에서 요청한 metrics를 반환한다.
4. predict
테스트 데이터에 대한 최종 예측을 한다.
predict(x, batch_size=None, verbose=0, steps=None, callbacks=None)
* evaluate vs predict
evaluate과 predict은 비슷해 보이지만 차이가 있다.
evaluate은 테스트 데이터와 정답을 모두 알려주고 정확도나 오차에 대한 값을 얻을 수 있고, predict는 테스트 데이터만 주어 어떠한 결과를 예측하는지 확인할 때 사용한다.
📌메모
지금까지 아주 간단한 DNN모델을 구성하여 MNIST 데이터 셋을 통해 모델을 훈련하고 평가하는 방법에 대해 알아보았다. 다음에는 DNN모델의 layer수를 바꿔보고 CNN모델을 적용해보는 방법에 대해 알아볼 것이다. 내용이 궁금하다면 아래 링크로 이동해서 보길 추천한다.
[AI⦁딥러닝] MNIST Data를 사용해보자2
📌 Intro MNIST 데이터 셋을 이용하여 ANN(DNN) 모델을 구성, 학습, 정확도 측정까지 진행해보았다. 이번에는 모델의 layer를 더 깊게 만들어보고 정확도를 비교해보도록 하자. 또 CNN모델을 만들어 학
krrong.tistory.com
📌참고
[1]https://blog.naver.com/PostView.naver?blogId=heygun&logNo=221513903948&parentCategoryNo=&categoryNo=23&viewDate=&isShowPopularPosts=true&from=search
[2]https://codetorial.net/tensorflow/mnist_classification.html