
💡 Intro
미션을 진행하면서 내가 만든 객체(Class)를 다른 컴포넌트에 넘겨야하는 시점이 등장했다. 일단 먼저 마주한 것은 Intent를 통해 넘기는 것이었다. intent의 putExtra함수를 사용하면 기본적으로 사용하는 자료형은 넘겨줄 수 있지만 내가 만든 클래스의 형태는 넘길 수 없다. 그럼 어떻게 해야할까?
바로 직렬화다. 그게 뭔지, 그리고 어떻게 사용하는지 알아보자.
❓ 직렬화?
직렬화는 메모리 내에 존재하는 정보를 보다 쉽게 전송 및 전달하기 위해 바이트코드 형태로 나열하는 것이다. 여기서 말하는 메모리 내에 존재하는 정보는 아마도 우리가 만든 객체가 될 것이다.
직렬화와 역직렬화는 객체의 상태를 저장하거나 전송하기 위해 사용된다. 예를 들어, 네트워크를 통해 객체를 전송하기 위해서는 객체를 직렬화해야 한다. 역직렬화는 이렇게 전송하거나 전송받은 데이터를 다시 원래 상태의 객체로 변환하는 것을 말한다.
❓ Serializable vs Parcelable
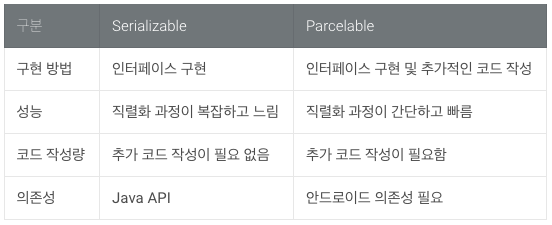
직렬화 방법은 크게 두 가지가 있다.
두 가지 방법 모두 객체 직렬화를 위한 인터페이스지만 구현 방법이나 성능 차이가 있다.
아래 표는 두 방법의 차이를 간단하게 보여준다.
❓ Serializable
더 자세하게 알아보자.
Serializable은 자바에서 제공하는 직렬화 기능이다.
사용법은 단순히 사용할 곳에 java.io.Serializable을 implements 하면 된다. implements하면 JVM 내부에서 자동으로 직렬화, 역직렬화를 처리한다.
자바 기본(primitive) 타입과 java.io.Serializable 인터페이스를 상속받은 객체는 직렬화 할 수 있는 기본 조건을 가진다. 이는 자동으로 이루어지며 추가적인 구현 코드가 필요하지 않다.
data class User(
val name: String,
val age: Int
): java.io.Serializable {
private fun printInfo() {
println("name ; $name, age : $age")
}
}하지만 몇 가지 단점이 있다.
- 데이터 타입추가와 변경에 대해 매우 엄격하다.
- 상대적으로 다른 포멧에 비해 용량이 크다.
- 하지만 Serializable은 객체의 상태와 메타데이터를 함께 직렬화하기 때문에 직렬화된 객체의 크기가 상대적으로 크다. 이는 객체의 모든 필드와 메서드 정보, 클래스 계층 구조 등을 포함하기 때문이다.
- 이와는 다르게 JSON이나 Protocol Buffers와 같은 포맷은 필요한 데이터만을 직렬화하고, 필드 이름이나 클래스 메타데이터를 생략하여 데이터의 크기를 최소화한다.
- 성능 저하 문제가 있다.
- Serializable은 Reflection을 사용하여 직렬화를 처리한다. Reflection은 프로세스 동작 중에 사용되며, 처리 과정 중 많은 추가 객체들을 생성한다. 이러한 객체들은 가비지 컬렉터의 처리 대상이 되고, 가바지 컬렉터가 할 일이 많아지기 때문에 성능 저하 및 배터리 소모가 발생한다.
Reflection
Reflection에 대해 간단하게 살펴보자.
Reflection은 런타임에 클래스의 구조와 멤버 정보를 동적으로 검사하고 조작할 수 있는 기능을 제공한다.
처리 과정 중 많은 추가 객체들을 생성한다?
Serializable 인터페이스를 구현한 클래스의 객체를 직렬화하거나 역직렬화할 때 Reflection API를 사용하여 객체의 필드, 메서드, 생성자 등의 정보를 분석하고 조작한다.
Reflection API를 사용하여 객체를 생성하는 과정은 객체를 인스턴스화하는 작업을 수행하며, 이 작업은 메모리 할당과 초기화를 포함한다. Serializable 객체의 경우 직렬화 과정에서 객체의 상태를 저장하기 위해 필드의 값을 읽고, 역직렬화 과정에서 필드의 값을 복원하기 위해 객체를 생성하고 초기화한다.
class User(val name: String, val age: Int) {
private fun printInfo() {
println("name ; $name, age : $age")
}
}
fun main() {
val user = User("크롱", 20)
val func = user.javaClass.getDeclaredMethod("printInfo")
func.isAccessible = true
func.invoke(user)
}클래스가 가지고 있는 메서드를 가져올 수 있다. 심지어는 private인 함수까지도!
외부에서 접근 가능하도록 수정한 뒤 실행까지 시킬 수 있는 강력한 기능이다.
❓ Parcelable
Parcelable 구현 생성기 | Kotlin | Android Developers
Parcelable 구현 생성기 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. kotlin-parcelize 플러그인은 Parcelable 구현 생성기를 제공합니다. Parcelable 지원을 포함하려
developer.android.com
Parcelable은 Android SDK에서 제공하는 직렬화 인터페이스다.
Parcelable은 내부적으로 Reflection을 사용하지 않게 설계되어있다.
Serializable과 다르게 개발자가 직렬화 처리방법(writeToParcel(), createFromParcel())을 명시해야하기 때문이다.
리플렉션 없이 동작할 수 있는 이유에 대해 좀 더 자세하게 말하면 Parcelable 인터페이스가 구현되는 클래스의 직렬화 및 역직렬화 메서드를 명시적으로 정의하기 때문이고, 여기서 정의된 메서드는 컴파일 타임에 검증되고, reflection없이 호출될 수 있다.
하지만 직렬화 처리방법을 명시해야 하기 때문에 보일러플레이트 코드 증가, 유지보수 복잡성 증가 같은 단점이 존재한다.
또, 직렬화 하는 모든 프로퍼티를 생성자 안에 넣어줘야 한다. (생성자안에 있지 않은 프로퍼티는 직렬화되지 않는다.)
하지만 kotlin-parcelize 플러그인은 Parcelable 클래스를 간편하게 작성하고 성능을 향상시킬 수 있도록 도와준다. 인터페이스를 직접 구현할 필요 없이 @Parcelize 어노테이션만 붙여주면 된다. 만약 Parcelable 클래스가 변경되어도 플러그인이 자동으로 Parcelable 구현체를 업데이트 시켜주기 때문에 유지보수성도 높여준다.
kotlin-parcelize 사용하기
1. build.gradle에 플러그인 추가
// build.gradle.kts(:app)
plugins {
id("kotlin-parcelize")
}
2. @Parcelize 어노테이션 추가
import android.os.Parcelable
import kotlinx.parcelize.Parcelize
@Parcelize
class User(val name: String, val age: Int) {
private fun printInfo() {
println("name ; $name, age : $age")
}
}
❗️ 정리
일반적으로 알려진 내용은 Serializable이 Parcelable보다 속도가 느리다고 알려져있다. 리플렉션을 사용해야 하고 이 과정에서 필요하지 않은 객체들을 생성하기 때문이다. 하지만 Serializable도 writeObject, readObject를 클래스에 맞게 로직을 구현하면, Serializable에서 생성되는 필요하지 않은 객체들이 생성되지 않기 때문에 속도는 비슷하다고 한다.
하지만 좋은 플러그인이 보일러플레이트 코드나, 유지보수 복잡성 증가와 같은 Parcelable의 단점들을 잘 보완해주고 있기 때문에 현재 내 생각은 Parcelable을 쓰지 않을 이유가 없다는 것이다.
❗️❗️ 더 나아가서..
지금 진행하고 있는 미션에서 모듈 분리를 하고있다. 가장 크게 도메인 모듈과 앱 모듈을 나누고 있는데 지금까지 모듈을 분리하는 이유를 고민해봤을 때 코드의 재사용성, 유지보수성 증가 정도이지 않나 생각한다. (갈수록 더 많은 장점들을 느낄 수 있지 않을까?)
Domain model vs Ui model
이게 무슨 말이냐고?
도메인 모델은 말 그대로 도메인에서 사용하는 모델을 말한다. 이는 도메인 로직을 가지고 있다.
Ui 모델도 말 그대로 Ui에서 사용하는 모델을 말한다. 하지만 도메인 모델과는 다르게 비즈니스 모델을 가지고 있지 않다.
도메인 모델과 Ui 모델, 각각의 구성이 거의 차이가 없기 때문에 굳이 나눠야 할 필요가 있나? 라는 의문이 들기 시작했다.
만약 필요하다면 왜 필요한 것일까?
만약 모델이 @drawableRes과 같은 android specific한 필드가 있다면 어떻게될까? 안드로이드 의존성이 생겨버린 해당 모델은 도메인 모델이라고 말할 수 있을까?
혹은 모델을 intent를 통해 다른 컴포넌트에 넘겨야 한다면 직렬화를 해줘야한다. 그러면 안드로이드 의존성이 생겨버린다. 해당 모델 역시 도메인 모델이라고 말할 수 있을까?
아마 그럴 수 없을 것이다.
또, 미션을 진행하면서 몸소 체험한 것인데 도메인 모델과 Ui 모델의 하는 일이 없고 역할이 같다고 해서 같은 모델을 사용하는 것은 좋지 않았다. 도메인 모델에 로직이 없다고 판단한 상황에서 Ui 모델만 사용하여 미션을 진행했었다. 그렇게되니 도메인에서 처리할 수 있는 로직들을 프레젠터가 모두 가지고 있었고 프레젠터가 굉장히 비대해지는 경험을 했다.
프레젠터를 다이어트 시키기 위해 모델을 나누고 프레젠터가 하는 일들을 각 모델에 부여했다. 그리고 Ui 모델을 사용하고 있던 모든 코드에서 Ui 모델과 도메인 모델을 분리하는 작업을 진행했는데 이게 굉.장.히 오래걸렸고, 복잡했다..
어떤 확장성이 생길지 모르기 때문에 도메인 모델과 Ui 모델은 분리하는 것은 필수적인 것 같다.
다음은 도메인 모델과 Ui 모델의 분리에 대해서 리뷰어님께 도움을 요청했을 때 받았던 코멘트다. 읽은 모든 사람들에게 도움이 되길.
처음에 명확한 기준을 잡기 어려우셨을거 같습니다.
아마 domain 모델과 ui 모델, 각각의 구성이 거의 차이가 없어서 굳이 나눌 필요가 있나? 라는 생각이 제일 크게 드셨을거 같구요.
당장은 이렇게 생각해보시면 좋을 것 같아요.
1. ui 요구사항을 먼저 정의해본다.
2. ui 를 그리기 위해 꼭 필요한 데이터가 있다.
3. 해당 데이터를 모아 ui 모델로 만든다. 이때 android specific 한 필드들이 들어가도 괜찮다. (@drawableRes 등)
4. 이렇게 만들어진 ui 모델의 구성이 도메인 모델과 완전히 같아도 상관이 없다.