
🐥 Merge Sort
Merge Sort는 재귀적으로 수열을 나눠 정렬한 후 합치는 정렬 알고리즘이다. 시간복잡도를 먼저 말하면 Merge Sort는 O(NlogN) 에 동작하는 빠른 알고리즘이다. Merge Sort를 이해하기 위해서 먼저 길이가 N, M인 정렬된 두 리스트를 합쳐서 길이가 N+M인 리스트를 만드는 방법을 알아야 한다.

위와 같은 정렬된 리스트 2개를 정렬하는 방법은 간단하다. 두 리스트의 가장 앞 원소를 확인하여 작은 것부터 채워 넣어주면 된다. 이미 두 리스트가 정렬되어 있는 상태이기 때문에 가장 작은 원소는 각 리스트의 가장 앞에 위치해 있을 것이고 두 개의 원소를 비교하면 두 리스트 중 가장 작은 원소를 찾을 수 있게 되는 것이다.
두 원소를 비교하는데 걸리는 시간은 O(1)이고, 리스트의 길이가 각각 N, M이니 총 O(N+M)시간 안에 두 리스트를 정렬할 수 있게 되는 것이다.
💻 구현(C++)
11728번: 배열 합치기
첫째 줄에 배열 A의 크기 N, 배열 B의 크기 M이 주어진다. (1 ≤ N, M ≤ 1,000,000) 둘째 줄에는 배열 A의 내용이, 셋째 줄에는 배열 B의 내용이 주어진다. 배열에 들어있는 수는 절댓값이 109보다 작거
www.acmicpc.net
#include <iostream>
#define MAX 1000005
using namespace std;
int N, M;
int A[MAX];
int B[MAX];
int C[2 * MAX]; // A, B를 정렬한 결과 저장
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin >> N >> M;
for (int i = 0; i < N; i++) {
cin >> A[i];
}
for (int i = 0; i < M; i++) {
cin >> B[i];
}
int aIdx = 0; // 배열 A를 확인하는 인덱스
int bIdx = 0; // 배열 B를 확인하는 인덱스
for (int i = 0; i < N + M; i++) {
// A를 끝까지 확인한 겨우
if (aIdx == N) {
C[i] = B[bIdx++];
}
// B를 끝까지 확인한 경우
else if (bIdx == M) {
C[i] = A[aIdx++];
}
// B의 원소가 더 큰 경우
else if (A[aIdx] <= B[bIdx]) { // 추가 설명
C[i] = A[aIdx++];
}
// A의 원소가 더 큰 경우
else {
C[i] = B[bIdx++];
}
}
// 출력
for (int i = 0; i < N + M; i++) {
cout << C[i] << ' ';
}
return 0;
}자세한 코드 내용은 주석으로 달아두었고, 추가 설명이라고 달아놓은 라인에 대해서만 조금 더 자세히 설명하려고 한다. B의 원소가 더 클 때는 A의 원소를 가져가는 것은 자명하다. 하지만 A의 원소와 B의 원소가 같을 때에도 A의 원소를 가져가도록 구현했는데 이러한 이유는 다음과 같다.
Merge Sort는 Stable Sort이다.
Stable Sort란 우선순위가 같은 원소들끼리는 원래의 정렬 순서를 따라가는 정렬방법이다.
이러한 성질을 만족시키기 위해서는 두 리스트를 비교할 때 두 원소의 우선순위가 같으면 앞 리스트에서 현재 보고 있는 원소를 뒤 리스트에서 현재 보고 있는 원소보다 먼저 이동시켜줘야 한다.
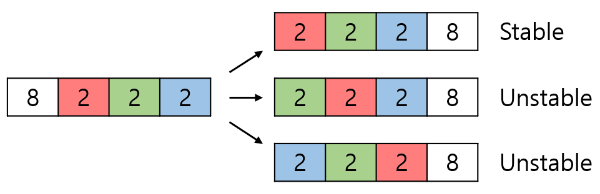
원소가 8 2 2 2 인 배열이 있고 우선 순위가 같은 2들은 다른 색상으로 표시했다. 배열을 정렬한 후 이 색상이 유지되는 경우 stable, 유지되지 않는 경우를 unstable이라고 한다.
⏱ 시간복잡도
Merge Sort의 과정과 시간복잡도를 알아보자.
다음은 Merge Sort의 전체 진행과정이다.

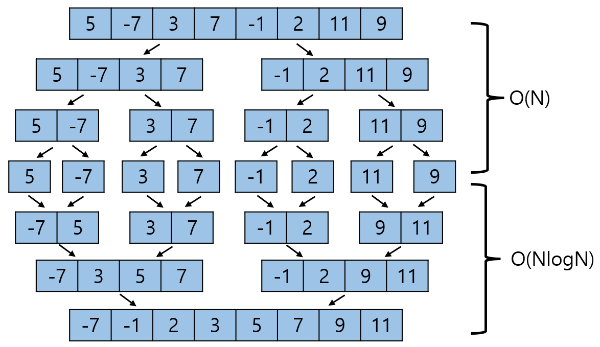
위 진행과정을 보면서 시간복잡도를 알아보면 다음과 같다. Merge Sort는 크게 배열을 분할하는 과정과 합쳐나가는 과정으로 분할이 가능하다. 분할하는 횟수는 위에서부터 1, 2, 4 ... 2^k이 된다. 분할하는 함수는 총 2N-1번 발생하고 시간복잡도는 O(N)이 된다.
배열의 길이를 N=2^k라고 할 때 합치는 단계는 총 k번 발생한다.(위의 예시는 N=2^3이고, 합치는 단계는 총 3번 발생하는 것을 알 수 있다.) 합치는 단계 한 번에서 여러 번 합치는 과정이 발생하는데 이전에 살펴본 것처럼 합치는 과정에서는 리스트의 모든 원소를 한 번씩 살펴보면 된다. 따라서 합치는 단계가 k번 발생하고 모든 원소를 살펴보기 때문에 시간복잡도는 O(kN) == O(NlogN)이 된다.
그러므로 Merge Sort의 시간복잡도는 O(NlogN)이 된다.
💻 구현2(C++)
2751번: 수 정렬하기 2
첫째 줄에 수의 개수 N(1 ≤ N ≤ 1,000,000)이 주어진다. 둘째 줄부터 N개의 줄에는 수가 주어진다. 이 수는 절댓값이 1,000,000보다 작거나 같은 정수이다. 수는 중복되지 않는다.
www.acmicpc.net
#include <iostream>
#define MAX 1000005
using namespace std;
int N;
int arr[MAX];
int tmp[MAX];
// 정렬된 두 배열을 Merge 하는 과정
void merge(int st, int en) {
int mid = (st + en) / 2;
int lIdx = st;
int rIdx = mid;
for (int i = st; i < en; i++) {
// 오른쪽 절반을 모두 확인한 경우
if (rIdx == en) {
tmp[i] = arr[lIdx++];
}
// 왼쪽 절반을 모두 확인한 경우
else if (lIdx == mid) {
tmp[i] = arr[rIdx++];
}
// 오른쪽의 원소가 더 큰 경우
else if (arr[lIdx] <= arr[rIdx]) {
tmp[i] = arr[lIdx++];
}
// 왼쪽의 원소가 더 큰 경우
else {
tmp[i] = arr[rIdx++];
}
}
// arr에 다시 저장
for (int i = st; i < en; i++) {
arr[i] = tmp[i];
}
}
// 배열을 쪼개는 과정
void merge_sort(int st, int en) {
if (st + 1 == en) {
return;
}
int mid = (st + en) / 2;
merge_sort(st, mid);
merge_sort(mid, en);
merge(st, en);
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin >> N;
for (int i = 0; i < N; i++) {
cin >> arr[i];
}
merge_sort(0, N);
for (int i = 0; i < N; i++) {
cout << arr[i] << '\n';
}
return 0;
}merge() 함수는 arr[st:en]을 정렬하는 함수다. 이전에 조건이 있는데 arr[st:mid]와 arr[mid:en]이 정렬되어 있어야 한다. 즉, 정렬된 배열 2개를 합치는 과정임을 의미한다.
merge_sort() 함수는 arr[st:en]을 정렬하는 함수다.
merge_sort() 함수의 base condition은 리스트의 길이가 1일 때다. 리스트의 길이가 1이라면 정렬된 상태와 마찬가지이기 때문에 추가로 정렬해줄 필요가 없다.
merge_sort() 함수에서 47, 48번째 라인에서 주어진 리스트를 절반으로 나누어 각각 정렬한다. 그리고 정렬된 두 리스트를 49번째 라인에서 합치면서 Merge Sort가 종료된다.
📃 정리
- Merge Sort의 시간복잡도는 O(NlogN)
- Merge Sort는 Stable Sort
참고
[1] https://www.youtube.com/watch?v=59fZkZO0Bo4&t=68s
[2] https://blog.encrypted.gg/955